如果你最近使用了各大厂商的SOTA模型,Claude Opus Sonnet,Codex 5.4,Gemini 3.1 Pro..... 大体你还是会感叹这些模型和比如三四个月之前的模型的区别。可以处理更复杂的任务,更长时间的调用和更稳定的输出。
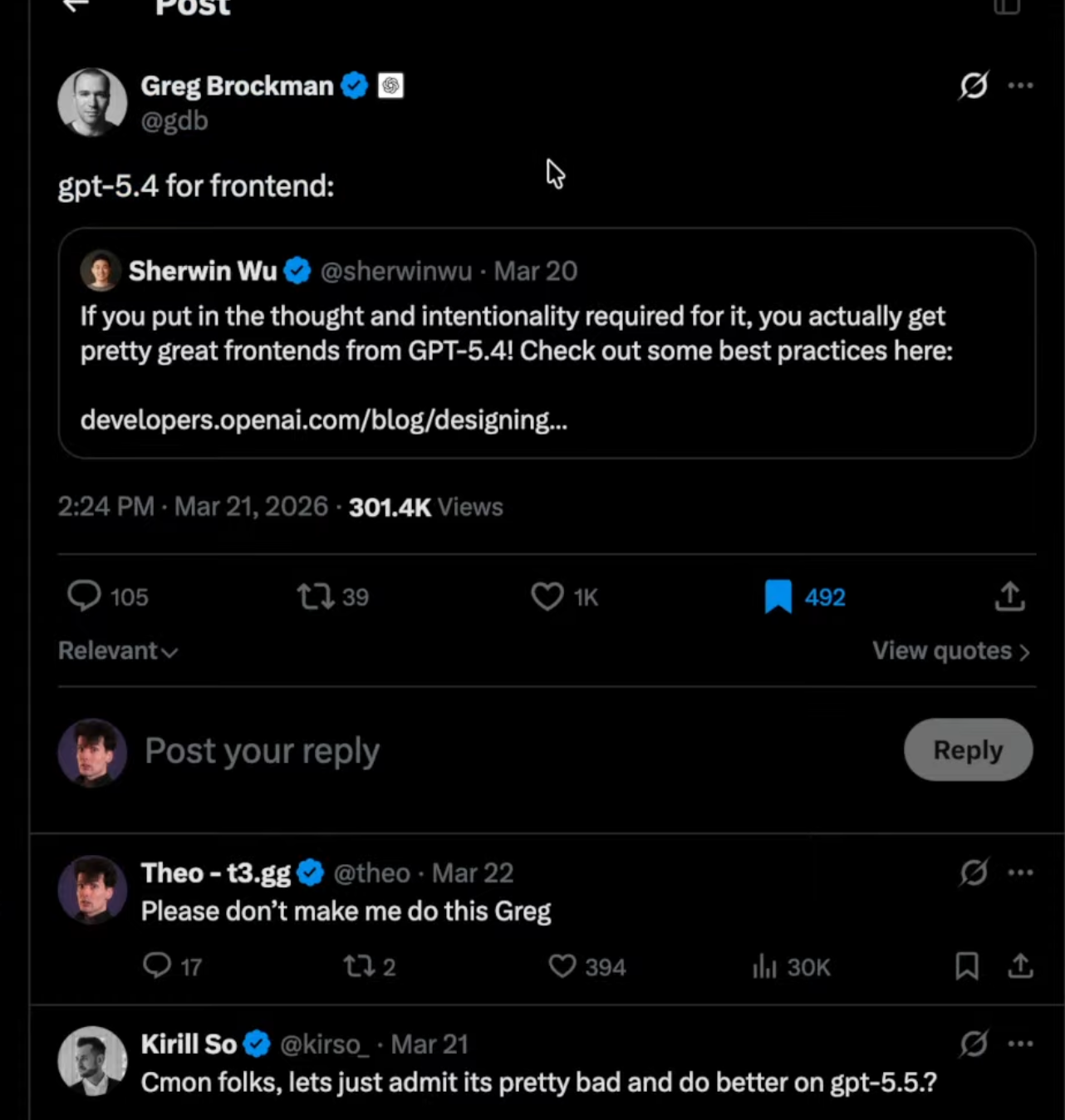
当然今天的主题是OpenAI和那篇有点招笑的文章。按照大家的使用反馈来看,相比于之前的codex5.3,GPT5.4模型在几乎所有的编程内容都有可观的进步,但唯独一个层面有明显的退步,那就是前端内容的生成不尽如人意。主要的问题可以归类为,偏执生成卡片类的内容,无法对齐的文字,匮乏的前端设计模版,等等。
对于其他能力这么强的5.4,OpenAI明显想要挽救其薄弱的前端能力,所以这篇文章就孕育而生。https://developers.openai.com/blog/designing-delightful-frontends-with-gpt-5-4
如果你只看标题,那好像OpenAI已经解决了上述的问题。但当你仔细阅读就发现OpenAI用了极度不专业的方式想去掩盖其最新模型在前端生成能力方面的不专业,那turns out,我们的Theo https://www.youtube.com/@t3dotgg (我非常看重的tech博主,专业级别的知识分享与吐槽和开源界的极大贡献者)就发现了OpenAI漏出的马脚。
文章中通篇说在正确的指导下,5.4可以达到生产级别的前端和交互能力,并给予了一些他们用过使用特定prompt和skills生成的前端展示内容。第一个问题就出现了,OpenAI的官网文章甚至无法添加一个横向scroll的功能让我看到被覆盖著的横向展示视频。这只是我个人阅读时发现的问题。
接下来在Theo的直播中,我们可以看到完整的前端的demo视频,比如那个游戏视频,游戏开始的一瞬间因为顶部文字改变导致顶部菜单ui的大幅度布局重绘,造成强大的视觉割裂感。这可是第一个demo。


还有就是,之后Theo扒出来OpenAi的Prompt源码,即便说了no card, default to card less 布局,但就像这个demo一样依旧是卡片套卡片。这应该是在5.4模型强化学习过程中导致的对card组件出现了奇怪的遵守。而且如果你仔细看,这个Miniature文字和组件的边缘重合了。

这些都是直观出现在文章中的内容,很滑稽甚至匪夷所思。这里还有OpenAI CTO的无脑转发。
根据Theo的分析,就如下面的图。因为这些模型都是经过强化学习过来的,目前训练会使用很多生成数据喂给新的模型,但somehow 5.4 模型在前端任务上没法拿到好的生成数据进行强化学习。

大致经验可以得出,5.3 codex 的前端风格模版大概有4个,opus4.6有10个 gemini3.1有15个。虽然模版数量并不能代表前端能力,但是很大程度体现其在强化学习中学到的技能。
总结
像 OpenAI 这样的 AI 明星独角兽,现在似乎染上了一种通病:极不情愿主动承认某代模型在特定任务上的退步。相反,他们会让研究员发布一些并不专业、甚至未经严格内部 Review 的内容来强行挽尊,最后昭告天下:“其实不是模型的问题,是你们的 Prompt 不够好”。但最终,这种公关话术还是会被开源社区的硬核开发者们锤得漏出马脚。
这同时也给我们提了个醒:在使用这些 AI 工具的过程中,时刻保持清醒,懂得灵活切换技术栈,摸清不同模型的能力边界,才是应对目前 AI 独角兽们“混乱期”的最佳策略。